A comprehensive guide to the security world’s most sought and least achieved goal.
What does least privilege mean?
In theory, the principle of least privilege is simple. It is:
“The principle that a security architecture is designed so that each entity is granted the minimum system resources and authorizations needed to perform its function.” [NIST]
Applied to identities, the principle of least privilege means that each identity (including both humans and machine identities) should only have the permissions it needs to do its work, and no more. Applied effectively, the principle of least privilege promises to protect you from the worst consequences of a compromised identity. For example, if a hacker successfully phishes an employee, the damage they can cause is limited by that employee’s permissions to key apps and data. The fewer permissions they have, the smaller the “blast radius” from an attack.
While least privilege sounds simple enough, applying it in the real world is complicated, and getting harder all the time, as the scale and complexity of hybrid- and multi-cloud deployments increases. In practice, a “perfect” implementation of least privilege isn’t possible. That would mean that no identity ever possessed permissions it didn’t strictly need for any amount of time, which isn’t realistic for any growing business. Be wary of any CISO who claims, “Mission accomplished!” It’s best to think of least privilege as an ideal to strive for. You’ll never get it perfect, but you can probably do better than you’re doing now, and any improvement makes you safer from both internal and external threats.
In this explainer, we’ll dive into the details of why least privilege is so difficult to achieve, and how you can get closer to achieving—and maintaining—that ideal.
Why is least privilege important?
Compromised Identities
Compromised Identities remain the most common primary cause for data breaches and ransomware attacks. There’s no surefire way to prevent identity compromise, but there are some preventative measures you can employ, including:
- Applying multi-factor authentication (MFA) or other phishing-resistant authentication
- Scanning your codebase for exposed credentials
- Training your employees to recognize and avoid social engineering attacks
A glance at the headlines for any given week, however, will tell you that even companies that do all of the above still fall victim to hacks and data breaches. It only takes one mistake to allow an attacker to gain access to an identity. From that point on, the severity of the damage will be determined by how quickly you can identify and respond to the attack, and, crucially, what privileges the compromised identity has.
For this reason, a prudent CISO assumes that they will not be able to prevent 100% of identity attacks; instead, they will focus on “de-risking” as many attack vectors as possible, starting with limiting excessive access. If a compromised identity holds sweeping privileges to read, write, delete or encrypt sensitive data, the result is likely to be catastrophic. By effectively applying the principle of least privilege, an organization can greatly reduce the consequences of a compromised identity by:
- Reducing the chance of an attacker gaining direct access to sensitive data
- Preventing an attacker from employing lateral movement or privilege escalation techniques to gain additional access.
Human error
Intentional attacks by outsiders aren’t the only threat to your systems and data. Even with the best of intentions, employees can make mistakes. In this context, any unnecessary privileges an identity holds to sensitve data are an opportunity for accidental damage or misuse. By eliminating unnecessary privilege, you greatly reduce the scope for catastrophic error.
Insider attacks
Much as we’d like to assume otherwise, intentional sabotage, theft, or misuse of data by employees is always a possibility. Verizon’s Data Breach Investigations Report for 2022 found that 20% of all breaches are caused by insiders. Effectively applying least privilege can thwart an insider attack in the same way as an identity compromised by external actors. An insider can’t steal data or damage systems they can’t access.
Why is it so hard to achieve least privilege
Two out of three organizations already list least privilege as a top security concern. Yet at the same time, Gartner estimates that 90% of cloud identities are too permissive. If we all want least privilege, why aren’t we able to achieve it?
Scale
The biggest change to the challenge of least privilege in the past two decades has been the sheer scale of the task. As data and apps moved to the cloud, the number and types of data assets have exploded. The rise of Infrastructure-as-a-Service (IaaS) led to the need to administer access to thousands of virtual machines, storage buckets, and relational databases, while the advent of data warehouses and data lakes meant millions of tables, rows, and documents. For example, one Veza customer manages around 13,000 tables per employee in Google BigQuery alone. This is before we even consider the need to govern access to hundreds of SaaS apps.
At the same time, the proliferation of machine users and service accounts has meant that there are more identities to manage than ever before.
The need to manage multiple cloud infrastructures, thousands of employees, and millions of objects already adds up to more individual access decisions than an organization can ever hope to make manually, and the number is only growing.
Complexity

The problem of scale is made more daunting by the increased complexity of access control. Each major cloud provider has its own Identity and Access Management (IAM) system: a unique language of permissions, encompassing users, roles, groups, policies and permissions governing access to data, workloads and apps. The user guide for AWS IAM alone stretches to over one thousand pages. To understand what any one identity can actually do requires deep expertise in multiple complex IAM systems.
Additionally, no one platform contains all the necessary information to understand access. To understand who can perform what action on what data, it is necessary to collate information from your Identity Platform (IdP), as well as all your cloud providers, data systems and SaaS apps.
It’s also true that almost no large organization is completely cloud-based. Whatever their ambitions for the future, the vast majority of organizations employ a “hybrid” deployment across cloud and on-premise systems. IAM, IGA or PAM tools are typically optimized to handle either on-prem or cloud privileges, but not both, making it impossible to establish a “single control plane” for governing access.
Visibility
To tackle the increasing scale and complexity of hybrid deployments, cloud infrastructure providers, data systems and business apps, organizations have been forced to seek out tools to simplify access management. One example is the use of Role-Based Access Control (RBAC) and groups in the identity platform to grant all the privileges needed for a particular role or function.
This approach promises to simplify the task of access management, but comes at the cost of visibility. To effectively implement least privilege, you need to be able to know who can perform what action on what data at a granular level. Instead, many IGA tools only manage what groups and roles are assigned to an identity, without giving you insight into the permissions associated with being a part of those groups and roles.
Unless you know exactly what access a role grants, you don’t really know what privileges an identity with that role has. This is especially true as the access granted by groups and roles can change over time. A group with “read only” in its name might actually have write or delete access to critical data assets, but the person assigning that role to a user has no way of knowing that’s the case.
Productivity
At the end of the day, most employees are directly incentivised to produce. Sales teams need to sign deals, data scientists need to produce insights, developers need to ship code, product managers need to release features. This need has always caused tension between security and governance teams—who are tasked with protecting and restricting access to systems and data—and other teams, who need those systems and data to produce results.
If security and governance are seen as too restrictive, too time-consuming, or damaging to productivity, employees will find workarounds to get the access they need without supervision. Such efforts lead to a “shadow” system, where local admins directly grant permissions in the tools they control without going through formal processes. This kind of access is unsupervised and unaudited, and can linger long after access ceases to be needed, leaving dormant accounts and excess permissions waiting to be picked up and used by an attacker.
Living with privilege sprawl
In many ways, this is a familiar problem. It’s the Second Law of Thermodynamics: entropy increases. Users will always push for expanded privileges, but rarely clamor to have them removed, and it’s always easier and faster to grant too many privileges, than too few. The inadequacy of existing governance processes leads to a proliferation of shortcuts and workarounds. In turn, each new shortcut and workaround makes it that much harder to make correct access decisions in the future. As one example, let’s explore the problem of group sprawl.
Groups were supposed to make it easier to manage access by combining access to apps and data into functional groups. Need to onboard a new front-end developer? Just give them access to the “Developer” group. However, even within a similar function, different employees aren’t all doing the same work on the same resources, so groups began to multiply. Soon, you have so many groups that it’s impossible to figure out what groups an employee should really belong to, so instead, yet another new group is created to encompass whatever access the IAM team needs to grant today.
As a quick exercise, try comparing the number of groups in your identity platform to the actual number of employees you manage. If groups were filling their intended function, you’d have far fewer groups than employees, but for most organizations, that relationship is flipped.
Group sprawl, and other forms of privilege sprawl, are a form of technical debt. Let’s call it “access debt”. Like all forms of debt, there are times when it makes sense to take it on. But, most large organizations are now drowning in access debt, with no clear path to paying it back.
Why manual access reviews don’t work
Current methods for achieving least privilege largely revolve around periodic manual reviews of access. However, manual reviews have historically proved ineffective at meaningfully reducing excess privilege. Reviews come in two flavors of awful:
IGA tools (or the rubber stamp of doom)

IGA platforms provide process automations and templates to set up access reviews, reducing the manual work required to facilitate access reviews. However, they typically only review access of human identities to groups or roles. They don’t reach the real permissions that a user has with respect to individual resources. In addition, since they generally rely on a HR tool as the source of truth for identities, they have a blind spot for non-human identities, like service accounts.
Since the decision-maker doesn’t have access to the information they need to make an informed decision, this type of review can be little more than a rubber stamp: a process followed to appease regulators and auditors, rather than a push for meaningfully improved access governance.
Manual compilation (or death by a thousand rows)
For this version of the process, detailed information on the permissions of identities are manually gathered from each individual app or data system—often via screenshots of a permissions page—and painstakingly collated into spreadsheets for decision makers to review and approve via the “stare and compare” method.

While this method can shed light on some of the blindspots of traditional IGA tools, it has some obvious drawbacks. One is that it’s a huge time suck. A quarterly access review shouldn’t take the whole quarter. The other deficit is that it relies on individuals to correctly and completely hunt down all access for a given identity. With no way to ensure accuracy, or comprehensiveness, it’s unwise to place too much trust in the results of a manually compiled access review.
Neither approach provides actionable results
Whichever type of manual access reviews you’re using, you’ll also encounter the problem of making the results actionable. Say a reviewer decides that access to a given table in the data warehouse isn’t necessary for a particular user. That decision is recorded in an IGA tool, or written down on a spreadsheet, but a month later, can the reviewer be sure that the access has actually been revoked?
Just as the process of manually making millions of access decisions doesn’t scale, nor does relying on human actors to remember each decision, identify who can remediate the access, know the process for requesting remediation, and follow up to make sure that remediation has occurred. Without automation and auditability supporting a reviewer’s decisions, they’re unlikely to be consistently applied.
A better way to approach least privilege
Identity-to-data visibility
Above all, to effectively implement least privilege, you need to be able to know the actual and effective permissions of an identity. Achieving this goal requires two components:
Granularity
Simply knowing the name of a role or group is not enough to know the real permissions of a user. What if your “read only” roles accidentally include “write” permissions? Would you ever know? In addition, you need to be able to account for IAM complexities such as nested groups, policy interactions and alternative access paths to be able to confidently answer the question of what action a user can actually perform on a given data object.
Translation layer for permissions
As already discussed, the AWS IAM manual runs to over a thousand pages. S3 storage buckets alone have over a hundred potential “permissions” to describe actions a user can take on the contents of a bucket. Business and security users tasked with applying least privilege typically aren’t experts in the minutiae of multiple IAM systems. These people need to be able to make decisions based on intelligible “effective” permissions. In other words, they need to see who can create, read, update and delete data.
Effective access reviews
Traditional access reviews are either hopelessly superficial, or impossibly time-consuming and unreliable. To fix access reviews, you need
- Visibility into the real permissions of all identities, across all of your systems, without having to go searching system by system.
- Full context for each permission, so that you can decide how to remediate unwanted access. For example, do you need to remove a user’s access to a role? Or change the permissions of that role? What other users would be affected by changing the role?
- Integration with ITSM and automation tools to make sure that the reviewers’ decisions are actually implemented.
- The ability to track access trends over time so that you can demonstrate the effectiveness of access reviews in reducing your attack surface.
Privilege automation
Remember that customer above with 13,000 Big Query tables to manage for each employee? Imagine trying to regulate access to those assets across every possible combination for several thousand employees and even more service accounts. Manual investigation and review will never uncover problems fast enough. You need tools that leverage automation to enforce least privilege and to surface and remediate best practice violations. We call this “Privilege Automation”.
Let’s take a simple example:
A company’s source code is hosted in a number of Github repositories. Employees and contractors from all over the world contribute to the codebase, but the ability to merge source code to production is intended to be held only by a handful of US employees. An employee based in China has admin privileges to some repositories, and accidentally grants permissions to merge code to production to an external contractor, also based in China.
To further complicate the issue, many developers working for the company use their personal Github handle to contribute code. This is common practice as Github handles function as a sort of resume that follows developers from job to job.
For anyone to discover this problem manually, they would need to look specifically at the list of users who can merge code to production on that particular repository. This may not happen until the next regular access review. Even then, the person looking would need to be able to tell by the contractor’s personal Github handle that they shouldn’t have access. They would then need to know who to approach to fix the issue, and follow up manually to make sure that the access was removed. The result is that dangerous excess permissions might remain active for weeks or months.
If this same company was leveraging Privilege Automation, they would employ tools to continuously monitor all privileges in Github, and compare local github users to their internal IdP to distinguish between internal and external users. Any violation of their policies, like an external contractor being able to merge code to production, would be detected as soon as it occurred. In response, a ticket would be automatically created in an ITSM tool like ServiceNow and assigned to the correct team, who would be alerted immediately. The ticket would not be closed until the violation was resolved.
Privilege Automation means getting closer to least privilege by supercharging the speed and reliability with which excess privilege is found and fixed.
How Veza enables least privilege
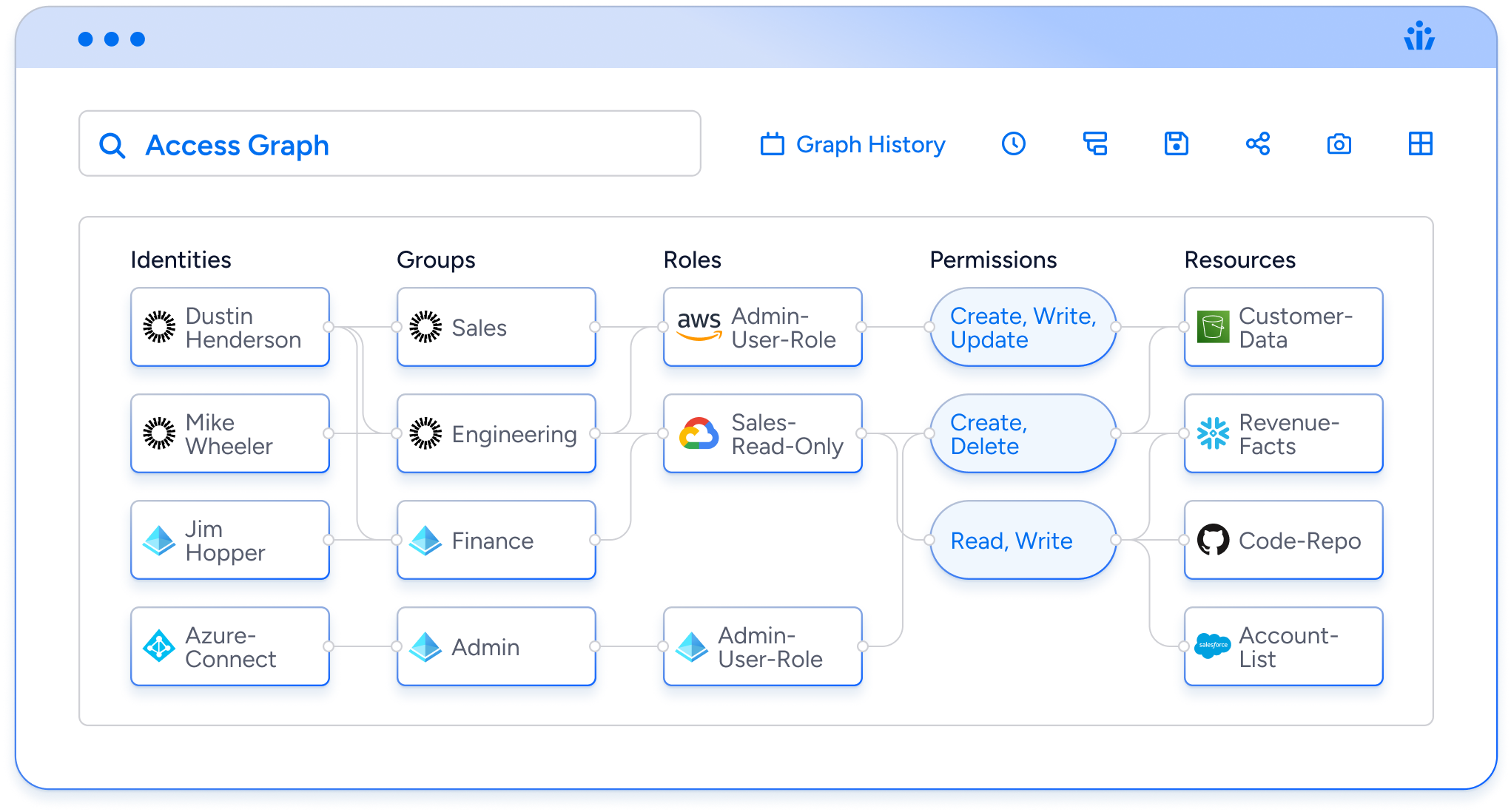
Veza is the Identity Security platform, built specifically to help you answer the vital question of “who can, and should, do what with your data?” Veza helps you achieve least privilege by:
- Providing visibility into the granular permissions of users, translated into simple and understandable language: create, read, update, delete.
- Continuously monitoring for excess privilege and automating remediation through integration with ITSM and notification tools.
- Enabling intelligent access reviews, based on the real, effective permissions of human and non-human identities, that end with actionable outcomes, backed by automation.
- Out-of-the-box access intelligence to find and fix misconfigurations, highlight overprivileged users and apply best practices in your role-based access control (RBAC).
To learn more about how Veza can help you pursue Least Privilege, schedule a demo today.