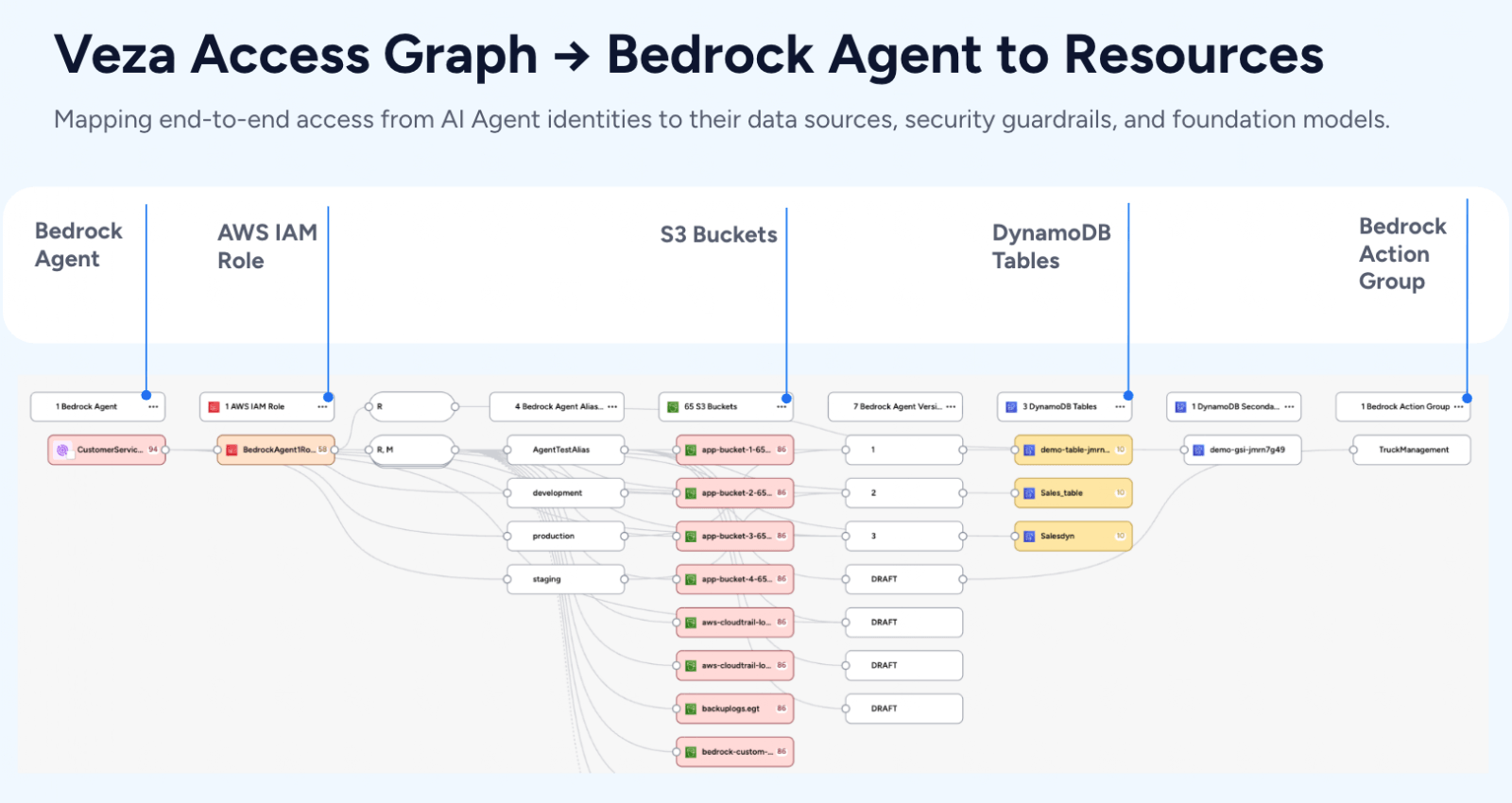
The shift of services and data to the cloud—especially the adoption of the major cloud providers like AWS—has been massive. For many companies, AWS is now the cornerstone of their infrastructure. But, as fast as the move to the cloud has happened, governance and security has been a little slower to catch up. Organizations are often still using processes and tools that belong to the era when almost all their sensitive data was housed on-premise in just one or two critical systems or databases.
A key difference between the on-prem infrastructure of the early 2000s and the cloud infrastructure enabled by AWS and other cloud providers is the scope and complexity of access controls that are now possible. Access for each individual identity, role, and resource can be set at a very granular level of detail, using several different policy types. While, in theory, this allows for exact control of access, it presents a daunting governance challenge: how to understand “effective permissions”.
Understanding the effective permissions of an identity essentially means understanding exactly what actions that identity can perform on what services and data. Understanding effective permissions is table stakes for successful access governance. If you can’t tell who can perform a given action, how can you effectively govern access?
Let’s take a look at why effective permissions are so tricky, and how we can put ourselves in a position to answer the foundational question of access governance in AWS: “Who has what access to what services and data?”
Challenges to understanding effective permissions
IAM policy complexity
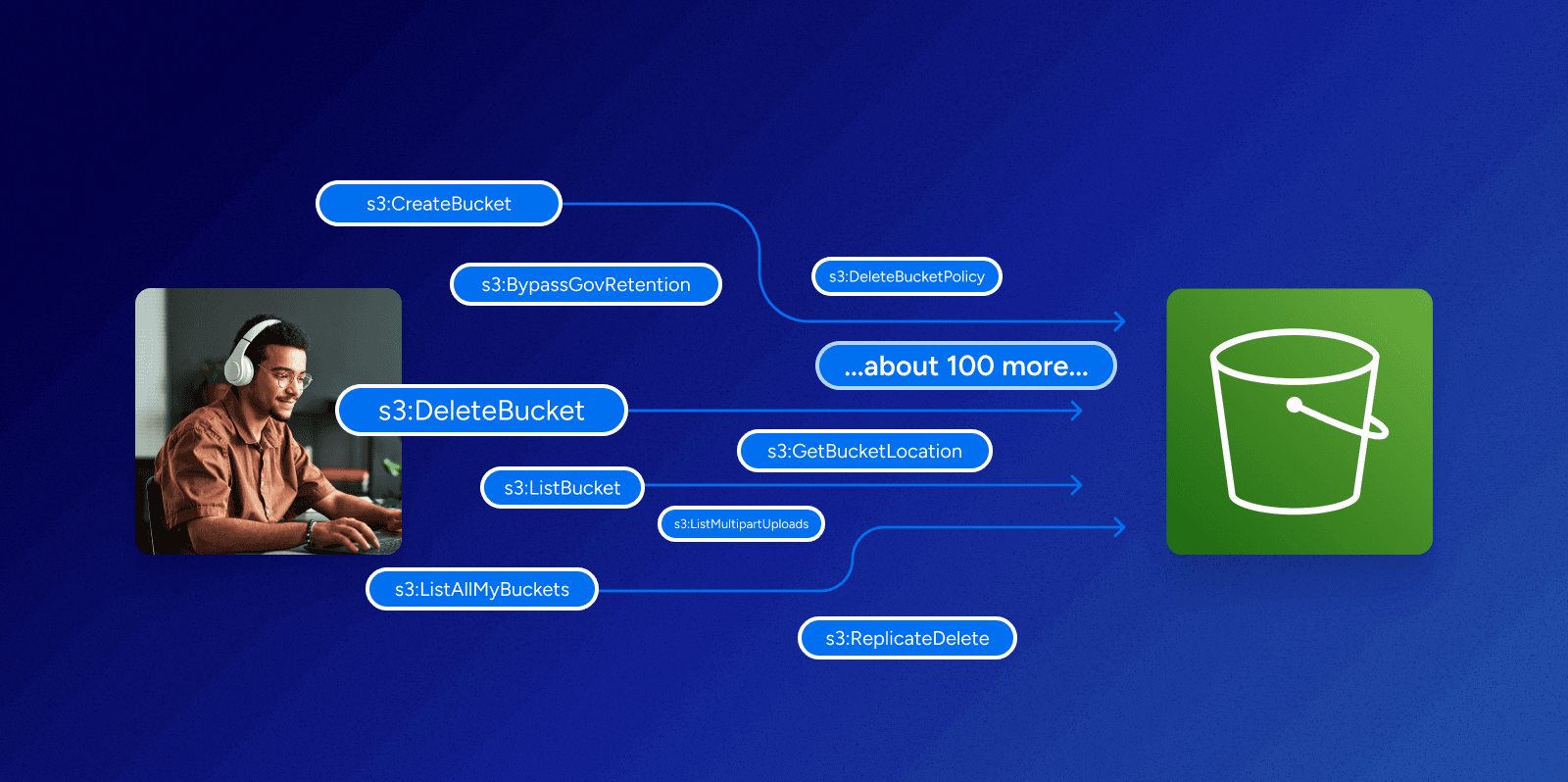
A typical AWS account might be home to many thousands of individual objects, of dozens of distinct types: Storage buckets, relational databases, data warehouse tables in Redshift, serverless Lambda functions, virtual machines, etc. AWS is a highly customizable environment that requires extremely granular permissions. Take the example of S3 storage buckets, just one resource type. To answer a simple governance question—like “can Dave delete data from the payment card details bucket?”—you need to engage with a model that includes more than a hundred distinct permissions. There isn’t a plain english description of what permissions mean and it’s not friendly to users who aren’t steeped in the minutiae of AWS.

Policy Interaction
Even assuming you understand the meaning of those 100+ permissions, you also need to understand that they can apply to many different “policies” attached to users, and also to resources, and that these policies can overlap and interact. In other words, it’s perfectly possible for two different policies to contain conflicting statements about what actions a role or identity is allowed to perform on a resource, and a complex set of rules is required to determine which policy “wins” in the event of a conflict.
This is a flow diagram, adapted from the AWS IAM docs, that shows how AWS decides if an identity is allowed to perform a given action.
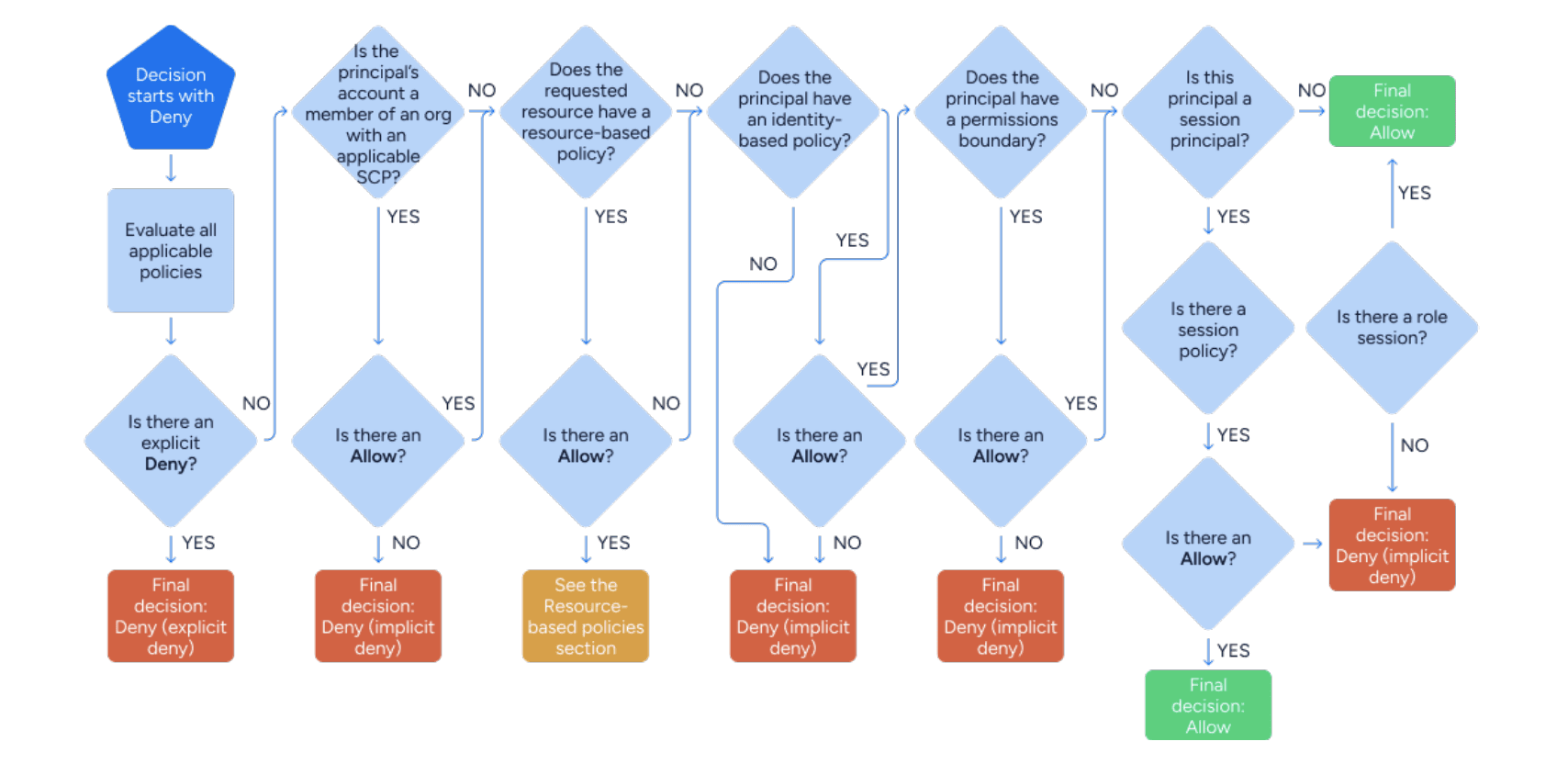
You can see that the final decision may require more than a dozen steps. From a governance perspective, it means that looking at any one policy can’t tell you what the final access outcome for an identity might be. This is important, because a lot of tools that purport to help you manage access in AWS only look at policies attached to an identity, or policies attached to a resource. They don’t look at the totality of your policies and extrapolate the final outcome. So you might believe an identity has access that they really don’t, or vice versa.
Siloed access data
Identities with access to AWS can be split into two categories:
- Local users – created directly in AWS, who can authenticate directly to AWS
- Federated users – managed by an identity provider like Okta or Azure AD who authenticate and access AWS via the identity provider.
This split creates governance challenges for both types of identities. For local users, all the information needed to determine their access is held within AWS IAM. However, governance tools, like legacy IGA platforms, typically take an identity provider or HR system as their source of truth for identities, meaning local AWS IAM users can be missed entirely.
For federated users, the information needed to determine access is split across two systems. Consider the following example:
- Okta user “Dave Deleter” is a member of the Okta group “Eng-US”
- Members of the “Eng-US” group are able to assume the “UIDev_USA” role in AWS IAM
- The AWS IAM role has permission to delete data from the “sigma-finance” storage bucket in AWS S3
In this example, Okta is aware of statements 1 and 2, and AWS IAM is aware of statement 3. Neither system by itself can connect “Dave Deleter” to his specific permissions on an S3 bucket.
How Veza can help
Unlike legacy identity and governance tools, Veza was built from the ground up to handle the complexities of the cloud, and to help organizations answer the vital question of “who can perform what action on what resources?”
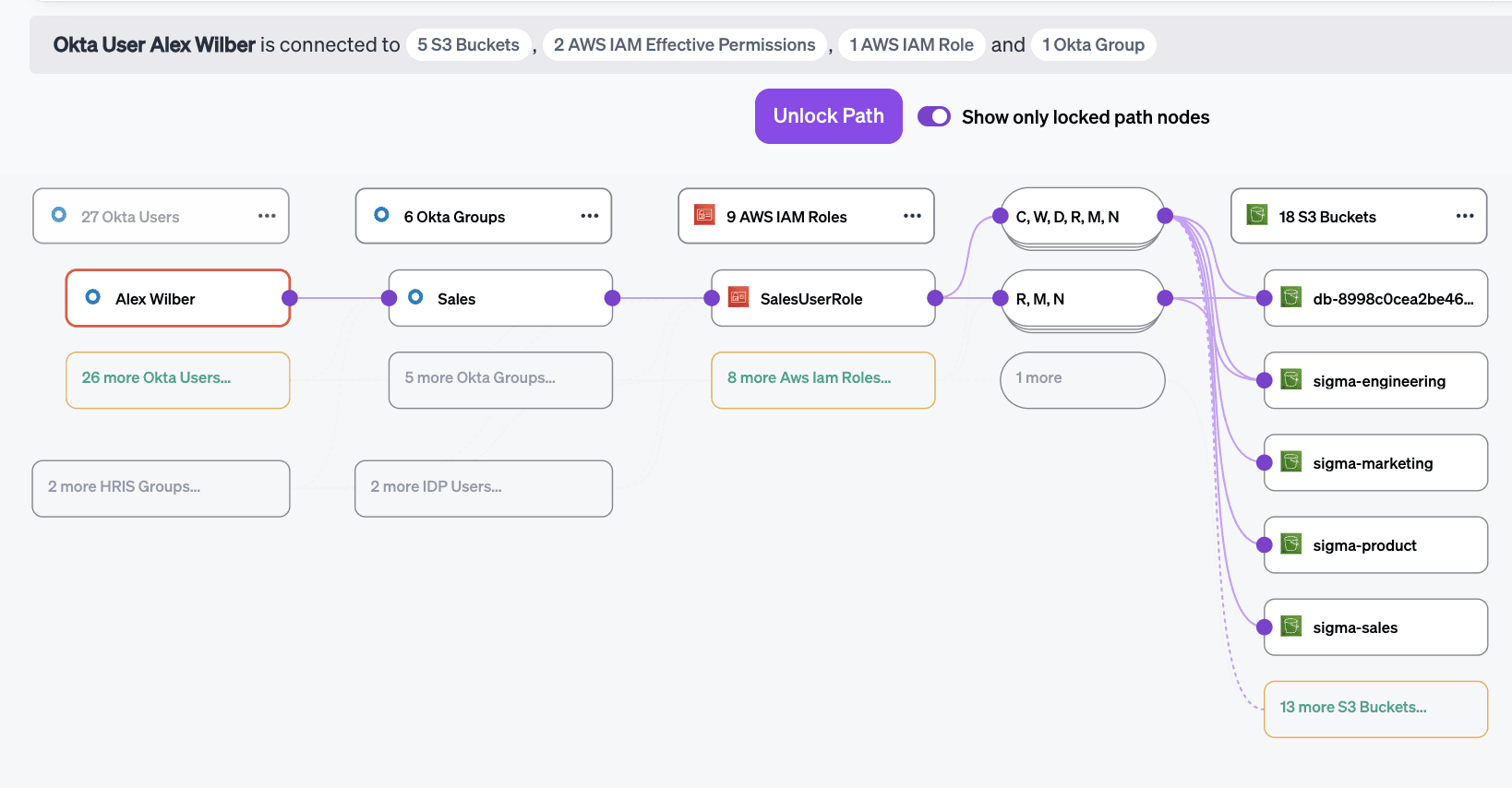
With Veza, you can easily understand the effective permissions of any local or federated identity in AWS, because Veza:
- Standardizes permissions: Veza translates permission data from across hundreds of systems into the simple, human-readable business language of Create, Read, Update, Delete. No need to be an expert in each platforms’ IAM system to understand what actions a user can take on a given resource.
- Resolves policy conflicts: Veza’s rich integration with AWS captures all relevant policies, not just those directly attached to a local identity. Using the same process as AWS IAM itself, Veza resolves policy conflicts to determine the effective access outcome.
- Unifies IdP and AWS IAM data: Veza connects to both AWS and your IdP, like Okta, Azure AD or Active Directory, and combines the data into a single graph database, allowing you to connect a federated user directly to their effective permissions to resources in AWS.
Learn more
To find out more about how Veza can help you successfully govern access to AWS: