Introduction
Veza has consistently pushed the boundaries of innovation in access and identity security. With the introduction of Access AI, Veza has revolutionized how organizations uncover hidden access insights by combining the power of Generative AI with our Access Graph and Access Intelligence products. Access AI enables users to express their intent and desired insights using natural language, making the process intuitive and user-friendly. Unlike older, rule-based NLP approaches, which often struggle with the complexity and nuance of identity relationships, Access AI leverages context-driven techniques and domain intelligence to deliver more accurate, actionable results. In this blog post, we will dive deep into the inner workings of Veza Access AI, exploring the challenges it addresses and the techniques employed to deliver meaningful results in a simple, digestible form to our customers. Fundamentally, this democratizes the Veza products, putting a powerful analytical tool in the hands of business teams and making identity security an operational reality for the entire organization.
The Complexity of Identity and Access Relationships
In the world of Identity Security, understanding and managing identity and access relationships can be a daunting task. Picture this: in order to reduce the potential blast radius of compromised accounts, an analyst needs to identify inactive identities that still have access to S3 buckets. Seems simple enough, right? But the reality is far more complex. A single identity might be connected to hundreds of S3 buckets through a tangled web of access paths involving Okta users, Active Directory (AD) groups, and AWS IAM Roles and IAM Policies, each with its own set of permissions. Moreover, a user might have local ACL permissions to S3 buckets independent of any AWS IAM policy. Untangling this intricate network of relationships is no small feat. But the challenges don’t stop there. Identities can be humans, but even more often, they will be non-humans, such as Service Accounts, VMs, Service Principals, API tokens, etc. The complexity of this query, involving numerous conditions, paths, and parameters, highlights the intricacies of identity and access relationships.
Faced with these challenges, we developed a very innovative Gen AI based solution that could simplify and streamline the process of uncovering identity and access relationships from a simple natural language input from the user. The result is Veza Access AI – a revolutionary technology that combines the power of Generative AI with our knowledgebase of permissions and entitlements and expertise to provide users with the insights they seek within the Access Graph. To fully understand the capabilities of Veza Access AI, let’s look at its design and a few parts that drive this system.
The Design Methodology
When designing Access AI, our primary objective was to determine the optimal technology stack for the key problems facing Identity Security. The breakthroughs of genuine intelligence and inherent training that accompanies Large Language Models (LLMs) was a natural place to start.
LLMs like ChatGPT are fundamentally built to predict the next sequence of words based on the given input. However, Veza Access AI’s effectiveness goes beyond this basic functionality. Its success lies in the careful design of prompts, relevant examples pulled from our metadata repository, and the use of Retrieval Augmented Generation (RAG) to enrich our integration metadata and graph permissions for identifying the best access paths.
We evaluated multiple language models from various providers to measure their performance, cost, and computational overhead under real-world workloads. Ultimately, we narrowed our choices to a handful—including Sonnet 3.5, Haiku 3, and Mistral—each optimized for specific tasks. While Sonnet stood out for its advanced reasoning capabilities and ease of adding new features, our overall architecture is LLM-agnostic. We expose a service layer that can interface with any general-purpose LLM or specialized domain-trained model, allowing us to pivot quickly to newer or more efficient models. This flexibility is backed by a rigorous validation and scoring framework that simulates diverse identity-security scenarios and complex graph traversals to confirm correctness, performance, and scalability. Finally, we orchestrate tasks through a dynamic execution graph powered by LangGraph, which routes each workflow to the most suitable model for discovering Identity and Access Paths, enabling us to maximize performance and accuracy across our solution..analysis.
Access AI leverages a combination of pre-trained transformer models for tasks such as initial entity recognition heuristic, an execution graph using LangGraph that employs LLMs to ascertain entities, relationships, and permissions, and ultimately, a query execution engine powered by our purpose-built language – Veza Query Language (VQL).
The Power of Veza Query Language
Before we look at the LLMs and the models that power Access AI, it is crucial to understand VQL. VQL is a simplified language designed from the ground up to query Veza’s Access Graph for entities, relationships, paths, and analytics across any environment. One of the primary goals of VQL is to abstract the intricacies of permissions traversal and interoperability across various products including Access Intelligence, Access Reviews, etc. This makes VQL the ideal choice for an execution engine for all natural language-like queries for Access AI.
Why Not Just Use SQL or Other Graph Languages?
We chose not to adopt SQL directly because, while SQL is widely known and extremely capable for relational data, it quickly becomes unwieldy when dealing with deeply nested graph relationships or advanced queries such as separation of duties (SoD). Many of these graph-oriented queries—especially in the world of identity and access—demand traversal across multiple identity sources and complex permission paths. Attempting to replicate those traversals solely in SQL can lead to overly complicated schemas and convoluted queries.
On the other hand, existing graph query languages (like Cypher) are powerful but often require deep familiarity with specialized syntax and direct graph representations, which can be daunting for users who are used to more traditional data models. In contrast, VQL offers a lightweight, domain-specific approach that draws on familiar SQL-like constructs for filtering and expressions, while retaining the ability to perform sophisticated graph traversals behind the scenes. This design choice makes VQL both powerful enough to handle complex access relationships and accessible for a wider range of users, all without forcing them to learn a fully specialized graph language.
Keeping VQL simple and extensible has been a key design decision, enabling us to leverage it as the execution and query engine for Veza Access AI. For instance, if we were to query for inactive AWS IAM users, we could simply type “Show AwsIamUser where is_active=false” and view all the results in any form – graphical or tabular. However, this is far from natural language and would not be widely accessible to non-technical business users.
VQL was designed to have filter expressions as a subset of PostgreSQL syntax. Since most LLMs are trained on SQL and are aware of building SQL, we leverage this pre-training and avoid a good chunk of training time and costs for our own spec and language. Within our tests, we’ve seen that this enabled the LLMs to generate accurate filter expressions when given sufficient context from our schema metadata. As an example, when a user queries inactive AWS IAM users, Access AI understands the context and generates a VQL query filter with a familiar SQL-like WHERE clause: “Show AwsIamUser where is_active=false”.
A few other examples of our simplified translation are shown below
| Natural Language Input | Output VQL Query |
| inactive AWS IAM users | Show AwsIamUser where is_active = false |
| Show me all AWS IAM User who can delete S3 bucket | Show AwsIamUser related to S3Bucket with effective permissions = ANY (‘DATA_DELETE’,’METADATA_DELETE’) |
| Show me all Google users who are not active and have decrypt permissions to Google KMS keys | Show GoogleWorkspaceUser WHERE is_active = false related to GoogleCloudKMSKey with system permissions = ANY (‘cloudkms.cryptoKeyVersions.useToDecrypt’,’cloudkms.cryptoKeyVersions.useToDecryptViaDelegation’) |
| show me s3 buckets which don’t have encryption enabled | Show S3Bucket WHERE default_encryption_enabled != true |
By abstracting the complexity of Access Queries and finding paths using VQL, and using standard SQL-like syntax for filter expressions as our design choice to leverage pretraining – we’ve improved our accuracy and observed a reduction in hallucinations and invalid queries when working with LLMs to generate queries.
Getting the Prompt Right
Crafting the perfect prompt is the most challenging aspect of extracting desired results from LLMs. Our experiments ranged from using smaller LLMs with small, manageable tasks to using one large LLM to accomplish multiple tasks at once. We’ve gone through a number of iterations before simplifying and splitting our prompts to create a final execution graph in Langgraph. Each prompt is designed to provide sufficient context for LLMs to comprehend the task at hand, along with leveraging Retrieval Augmented Generation (RAG) techniques to provide LLMs with context for data originating from multiple sources, such as the Veza query repository examples, schema metadata, permissions mapping, and applicable properties.
These techniques help provide LLMs with the most relevant metadata before tackling a specific task. Let’s consider a simple example: “Show me all the access Aaron has.” The first step in addressing this query is to understand the user’s intent. With potentially hundreds or thousands of entities to consider, our preprocessing leverages search and information retrieval techniques to perform a lookup and rank relevant entities before invoking the initial LLM call. It then feeds this refined context to the Entity Identification task. Another layer within our agent graph also involves leveraging pre-trained BERT models on our access graph metadata and synthetic user inputs to improve our confidence for entity recognition before providing LLMs with our Graph Node Types. All of this ensures that we identify Node Types requested by the user as accurately as possible.
Reducing Hallucinations and Favoring Correctness
Another key challenge with language models is their tendency to generate hallucinations in various scenarios. During the initial stages of designing prompts and tasks, hallucinations and undesired results were frequently observed in tasks such as Entity Inference, Path Finding, and Permissions Identification. To mitigate hallucinations, it is crucial to provide clear context, examples, and constraints within the prompts – striking a balance between minimizing inaccuracies and maintaining flexibility. Simplicity is key to creating effective prompts.
Despite implementing these measures, there is still a possibility of encountering hallucinations from Large Language Models (LLMs). With Access AI, we chose to prioritize syntactic and semantic correctness in the generated queries. This minimizes the risk of invalid requests reaching our graph while preserving user intent as accurately as possible. If the exact entity cannot be identified, we display the closest match; syntax errors are handled through post-processing, and semantic correctness is enforced via clearly structured prompts and fallback mechanisms.
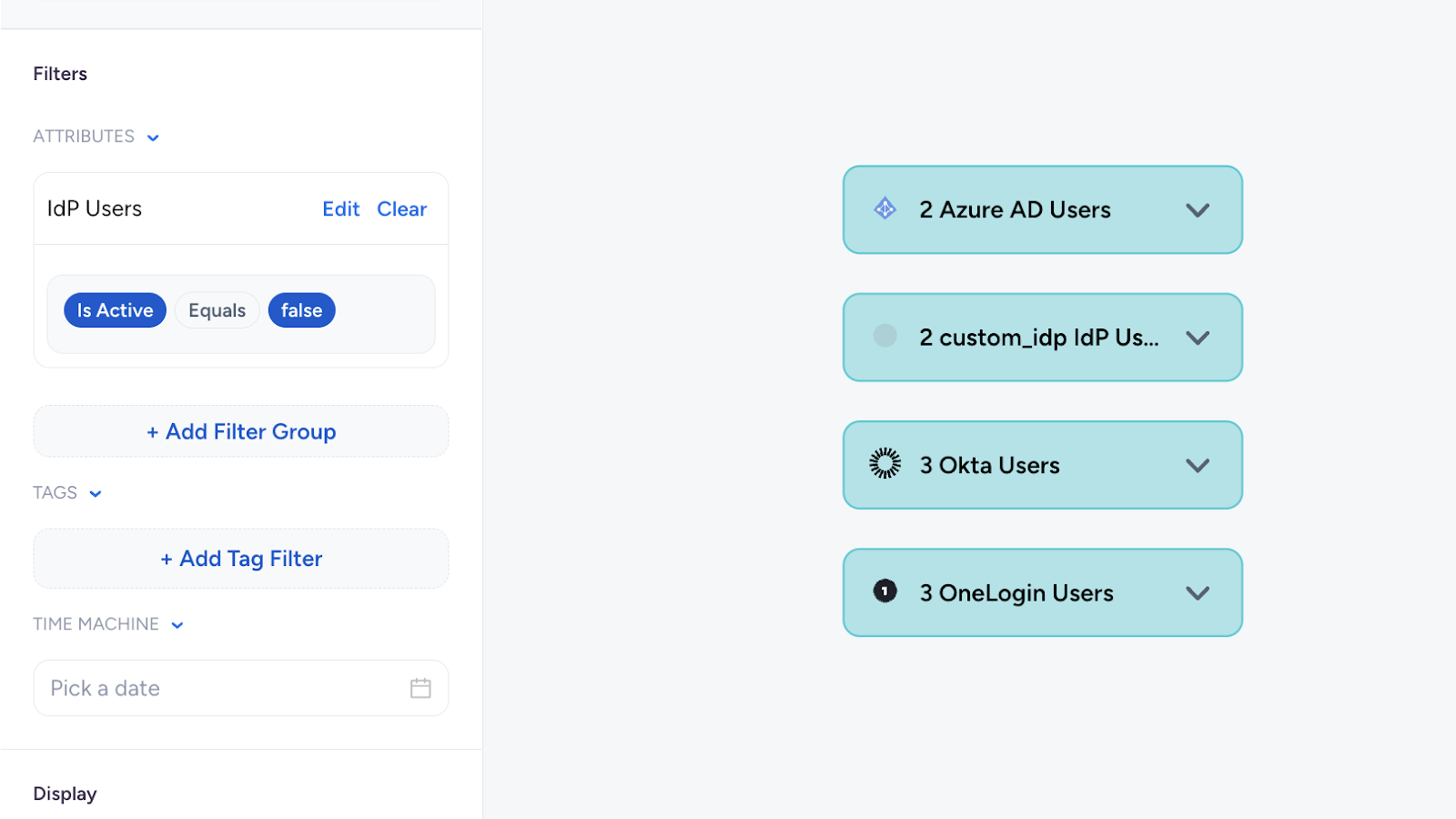
Let’s take an example. When a user enters a query like “show me all inactive users,” Access AI may encounter ambiguity in determining the specific type of `User` being requested. The system must disambiguate between various user types, such as OktaUser, Azure AD User, or other local user users. Additionally, the query might be interpreted as a request for all inactive users, regardless of their associated integration or type. To handle these scenarios, our execution is designed to display all relevant user types, as illustrated below. This approach enables users to further refine their search by applying filters to select a specific user type or explore additional details.
On the other hand, if a user queries for `show me all inactive identities with access to secrets in aws`, we know that the user may be querying for Aws Iam Users and we show the results ( if they exist ).
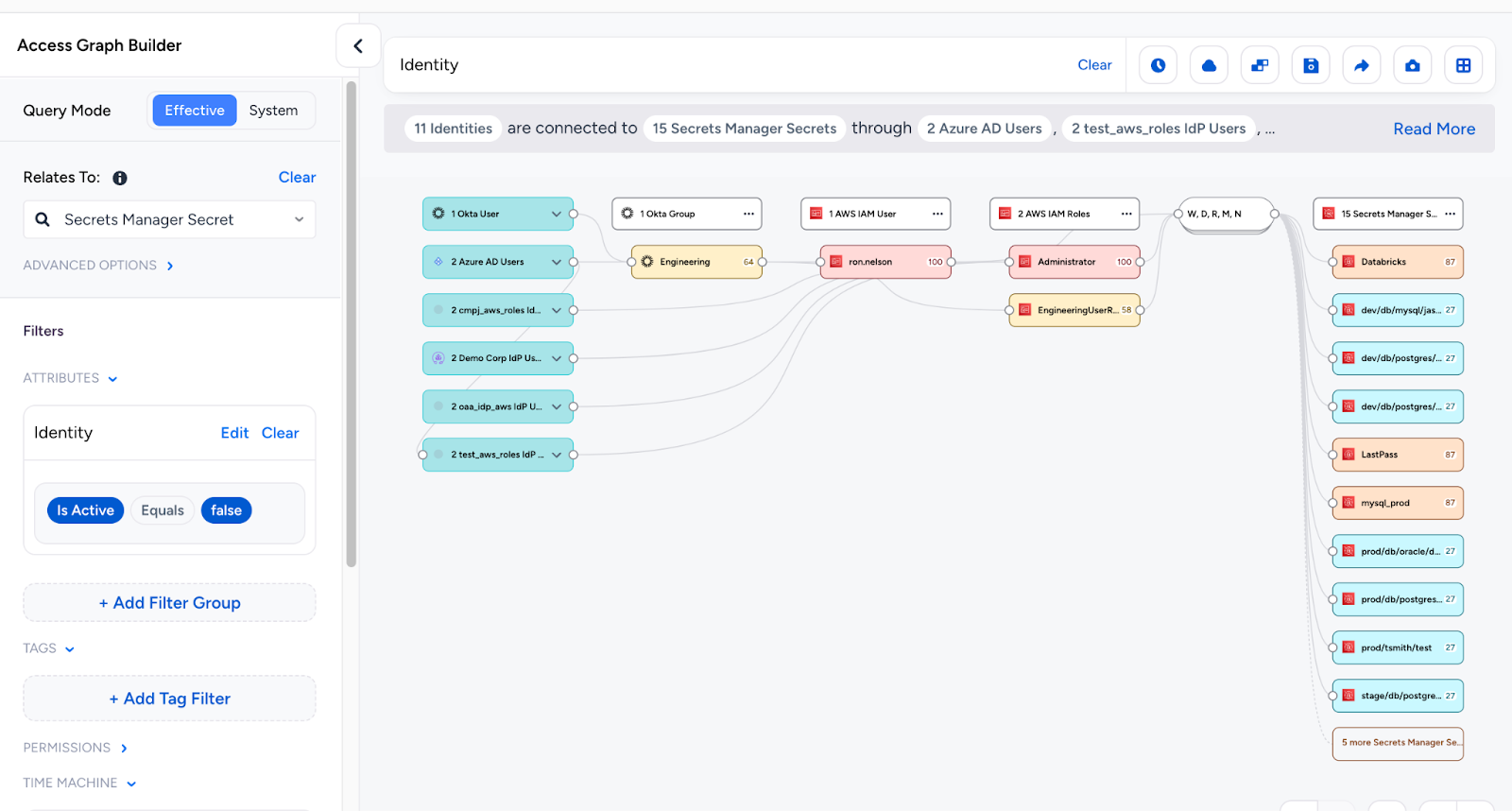
The primary objective is to prioritize correctness, ensuring an optimal user experience. The end goal is to implement a `chat-like` interface that allows users to rectify misinterpreted queries and retrieve accurate results based on VQL. This interface will enable users to provide feedback, refining the system’s inference capabilities and delivering precise information aligned with the user’s intended search parameters.
Agentic Framework for Veza Access AI
While the primary focus of this article has been on answering the question “who has access to what,” Veza Access AI’s potential extends far beyond search. With the rich dataset offered by each of our integrations, we have built an engineering foundation that enables the development of future AI agents for Veza. As models grow smarter and our data richness increases, these AI agents can provide users with deep risk insights, monitor and alert them for anomalies, aid in writing assessments easier and more efficiently, use Veza products with natural language interaction, and many more.
Our core foundation is an agent-based framework that relies on our data-rich APIs, Bedrock, Transformer Models, metadata stores, and LangGraph agents. The combination of these components has empowered us to plan for and build true intelligence in our products everywhere. Here’s a simplified view of the diagram that showcases our ability to integrate the power of AI into various parts, ensuring that we have a data-rich foundation and flexible layers to iterate faster and add intelligence to all our products.
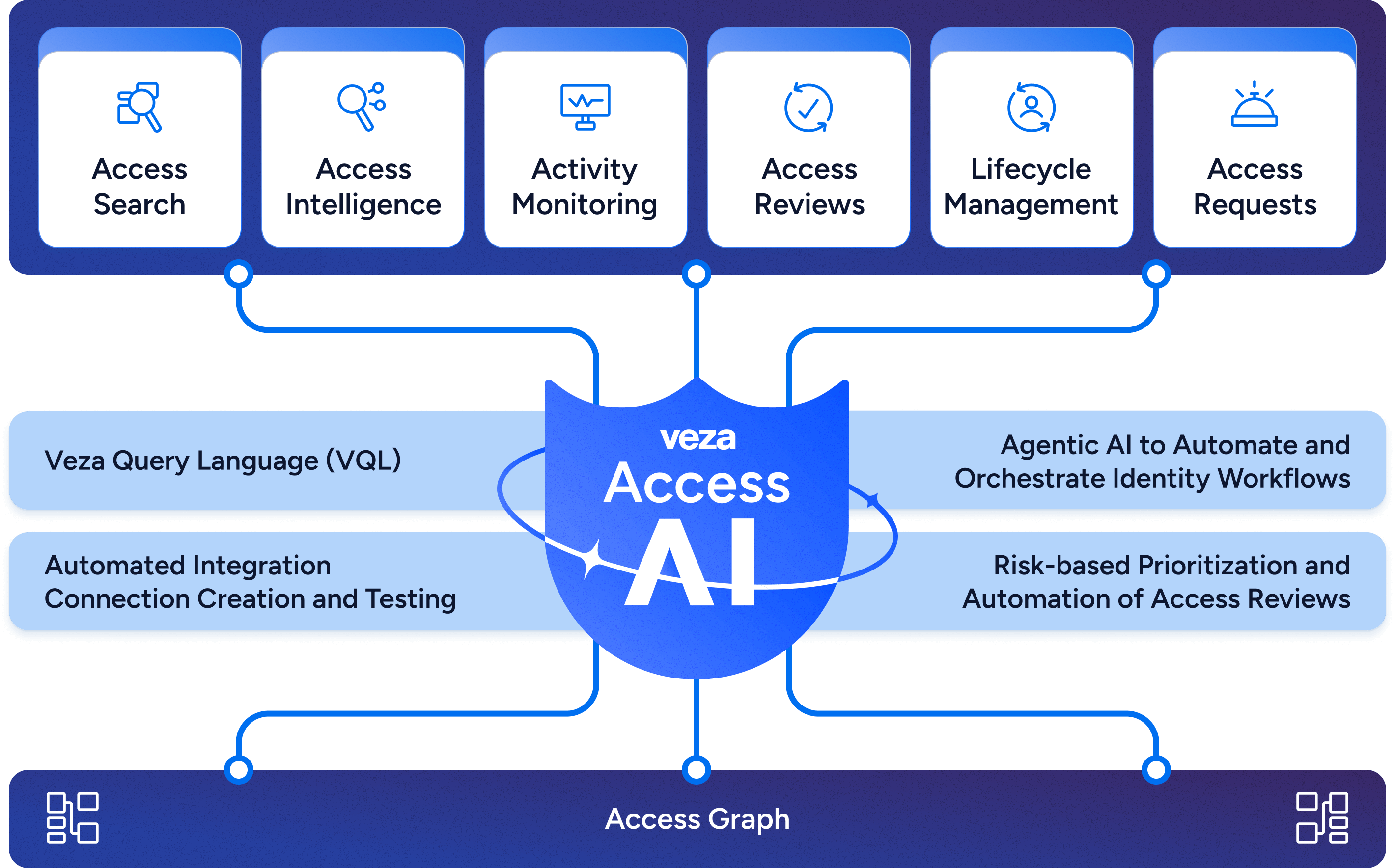
Lessons Learned
Our exploration of alternative methods to improve Veza Access AI Search has provided important insights that will inform our future strategies. Although some approaches did not meet our expectations, they have enriched our understanding of the challenges and opportunities in this field.
One critical lesson is the need to strike a balance between performance and complexity. We tried synthetic data generation and pre-train a BERT model using our meta graph, but we faced challenges where pre-trained inputs lacked the flexibility of real-world queries. LLMs helped us overcome this issue and helped us understand user intent very well. Moving forward, we intend to strategically utilize pre-trained models for auto-completing user queries and inputs for Access AI to achieve better performance compared to solely relying on LLMs. Despite these obstacles, our exploration has strengthened our confidence in the capabilities of LLMs and fine-tuning techniques for specific tasks like entity identification. As we progress, we will apply these lessons to refine our approaches and concentrate on creating solutions that balance performance, adaptability, and extensibility. As with all engineering designs, our current strategy helps us balance accuracy and performance while enabling rapid iteration to develop and adapt to evolving requirements. As an example, we could in the future, also employ Chain of Thought reasoning, verification agents, and a `chat-like` interface to better understand the user while providing highly relevant results.
A final lesson we’ve learned while working with LLMs and Generative AI is the importance of user experiences. Working with LLMs inherently needs a great experience and a feedback loop that can help us improve and provide the user with a good mechanism to correct the outputs of LLMs.
Conclusion
Veza Access AI marks a notable progression in access and identity security. By leveraging Generative AI, our Access Graph, and thousands of built-in assessments, Veza has developed a solution that streamlines the discovery of hidden access patterns and delivers pertinent access insights to users. Access AI achieves an unprecedented level of intelligence, distinguishing it from conventional methods and bringing us closer to democratizing the Veza Access Graph.
As Veza continues to innovate and expand its capabilities, Access AI will undoubtedly simplify how organizations navigate the complexities of identity and access relationships. It will empower security professionals and business users with the tools they need to effectively protect their digital assets. With the groundwork laid for future training, embeddings, and our agentic frameworks, Access AI will infuse intelligence capabilities into all our products and services.
From Complexity to Clarity—Your Next Steps with Veza
Veza Access AI isn’t just a leap forward in identity security—it’s a paradigm shift. By harnessing the power of Generative AI, we’ve transformed the labyrinth of access relationships into an intuitive landscape navigable by natural language. This democratization of access intelligence empowers every stakeholder, from security analysts to business users, to gain actionable insights without the steep learning curve.
But understanding is just the beginning. To truly fortify your organization’s security posture, it’s imperative to delve deeper, explore further, and take decisive action. Here’s how you can continue your journey with Veza:
🔍 Discover the Power of Access AI
Uncover how Veza’s Access AI leverages natural language processing to provide instant insights into your organization’s access landscape.
👉 Explore Access AI
📊 Dive into Access Intelligence
Equip your team with the tools to detect privileged users, dormant permissions, and policy violations using over 500 pre-built queries.
👉 Download the Access Intelligence Data Sheet
🎯 Benchmark with the State of Access 2024 Report
Gain industry benchmarks and insights to understand how your organization stacks up in achieving least privilege and robust access controls.
👉 Access the State of Access 2024 Report
Ready to transform your identity security strategy?
Schedule a personalized demo and see Veza in action.
👉 Schedule a Demo